Introduction
Artificial intelligence (AI) is machine intelligence that is meant to imitate human brain processes [1-3]. With rapid advances in computer science, AI has recently been applied to many areas by large information technology companies. The recent defeat of a human Go champion by Google DeepMind AlphaGo surprised the public worldwide and demonstrated that AI may even be superior to the human brain in some decision-making processes [4].
Precision medicine, defined as tailored diagnosis and therapy for an individual patient, is an important emerging concept in future medicine [5]. The recent explosion of clinical, biological (genomic and immunological), and imaging data is creating a path for such personalized medicine. Integration of these multiple streams of information and appropriate interpretation thereof are important, and AI techniques may be useful in this respect.
Stroke medicine may be a suitable application for precision medicine and AI techniques because of the vast amount of data and multidisciplinary approaches used in making clinical decisions [1,6]. In particular, brain imaging, which is the key factor in stroke management and forms the basis for numerous complex go/no-go decisions, is an attractive subject for AI techniques. In this review article, we will briefly review AI techniques in stroke imaging and discuss their potential clinical applications and future roles.
AI
Machine learning is a technique of AI that is widely used in interpreting medical images. It recognizes patterns of imaging information and renders medical diagnoses [3]. Supervised and unsupervised learning are widely used typical machine learning types. Deep learning is a more recently developed technique, which mimics the human brain, using multiple layers of artificial neuronal networks.
Machine learning
Machine learning is typically classified into supervised and unsupervised learning [1-3]. Supervised machine learning uses a training dataset labeled by humans to define the desired or known answers. It may expedite classification or regression processes with large datasets and would be useful for predicting or discriminating clinical outcomes. However, it requires a human labeling process, which is often cumbersome and time-consuming. Examples of a supervised learning method include the support vector machine, decision tree, linear regression, logistic regression, naive Bayes, and random forest methods. In contrast, unsupervised machine learning does not use human-defined answers; instead, it seeks to identify hidden patterns, on its own, in large datasets, which are usually invisible to humans. Therefore, unsupervised learning may be useful in seeking novel disease mechanisms, genotypes, and phenotypes. Examples of unsupervised learning include K-means, mean shift, affinity propagation, hierarchical clustering, and Gaussian mixture modeling.
These two learning methods can be easily distinguished by whether or not they use human feedback. If a machine is to be developed that could distinguish between ischemic and hemorrhagic stroke images, machines with a supervised algorithm will be trained with human pre-labeled correct answers, while those with an unsupervised algorithm will learn to categorize images into two or three groups according to certain patterns, which they would identify during learning processes, by themselves.
In machine learning, variables used as input data are generally referred to as features; these can be numerical or nominal values. Because the performance of machines is variable according to the features inputted, it is important to select and extract features from the data appropriately. The input features are usually determined by researchers and data scientists. Nowadays, various feature selection methods have been developed to enhance the selection process and establish machine models with high accuracy. Using these features, machine learning algorithms determine the optimal decision boundaryŌĆöselecting features and developing a modelŌĆöto conduct a set task. For imaging data, various image features, such as the size, location, shape, and signal intensities of the lesion, can be used for machine learning. Machines can distinguish and make use of additional imaging features, such as texture information, e.g., signal intensity gradient, and skewness, which are not discernible by humans [3,7].
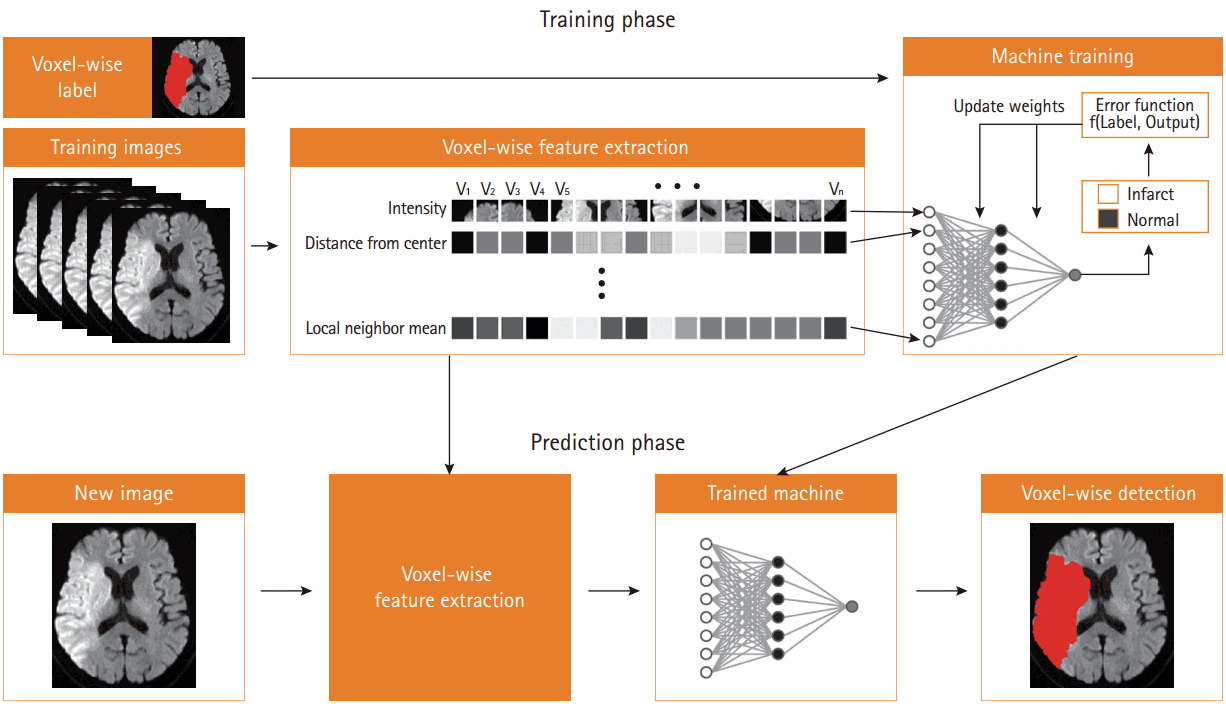
Figure 1 demonstrates an example of automated segmentation of infarct lesions using supervised machine learning techniques. In the training phase, machines learn how to detect infarct lesions using various voxel-wise imaging features under the supervision of human-labeled answers. In this phase, the machine attempts to develop an optimal model to perform the task with selective input variables. In this case, the machine determines several image features and devises a model to automatically draw stroke lesion margins. In the prediction phase, the machine encounters a new image, and applies its determined mechanism to the selected image.
There are two representative machine learning algorithms, the support vector machine (SVM) and the artificial neural network (ANN).
SVM
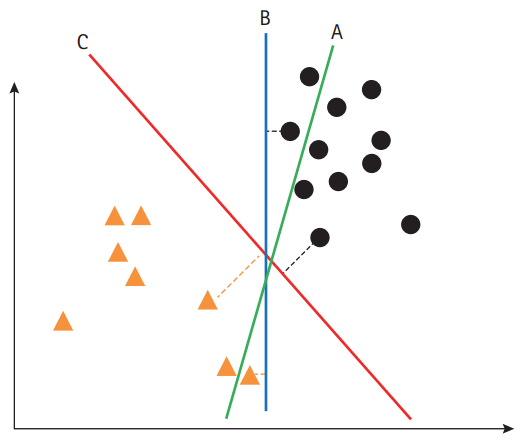
SVM is a supervised machine learning method, which is useful for developing a model to allocate an object to one category or the other. Therefore, SVM is widely used in clinical imaging analysis, which categorizes or classifies a diagnosis. SVM constructs a hyper-plane in a high-dimensional space as the decision surface. To accomplish better performance, the margin of separation between classes needs to be maximized (Figure 2) [8]. For a non-linear classification, SVM uses the kernel technique, which implicitly converts the input features into high-dimensional feature spaces. Therefore, selection of the kernel should be appropriate, to avoid increases in error rates.
ANN
ANN is inspired by biological neural networks. An artificial neuron receives inputs from other neurons, integrates the inputs with weights, and activates when a defined condition is satisfied (Figure 3). ANN consists of input, output, and hidden layers. The input layer receives observed values, while the output layer represents the target (a value or class). The layers between input and output layers are called hidden layers. Typically, nodes within each layer are all connected to each other between the layers. ANN is very flexible in terms of application to various data types, and can be applied to conditions in which other statistical analyses are unsuccessful. However, ANN has limitations in that it is susceptible to data-overfitting, and tends to require a long computation time.
Deep learning
Deep learning is a more recently developed technique of machine learning, which mimics the human brain using multiple layers of ANN. Although there are no explicit criteria on the threshold of depth to discriminate between shallow and deep learning, the latter is conventionally defined as having multiple hidden layers.
Recurrent neural network (RNN) is a subtype of ANN that uses connections between nodes forming a cycle with a one-way direction (Figure 3). RNN can use the temporal memory of networks, which is in contrast to other typical neural networks with feed-forward structures. Therefore, RNN is specialized for the processing of temporal data, which include recognition of natural language, handwriting, and speech.
Convolutional neural network (CNN) also uses a neural network but assumes that the CNN input signal has geometric information, such as the receptive field in the visual cortex, individual cortical neurons here belong to the receptive field in the visual cortex, not to CNN, therefore we think that current form would be better [9]. CNN nodes connect to each other in a geometrical structure, not showing all-to-all connections (Figure 3). In imaging analysis, nodes in the input layer are arranged to produce a convolution of a small part of the image (kernel) [3]; this kernel then moves around the image to produce an output value. Remarkably, the CNN algorithms do not require a computing process as a first step, minimizing human effort in selecting and designing features.
Consideration
There are several issues to be addressed before machine and deep learning techniques can be introduced into clinical practice. A machine learns from various imaging features by itself, including those even unrecognizable to humans. Its technical mechanisms and logic are mostly impossible to understand. This ŌĆ£black boxŌĆØ nature may be against the current concept of evidence-based medicine. Moreover, a lack of understanding of the working mechanism may raise legal and ethical issues in using the machine model in real-world practice. Overfitting problems also need to be addressed. Overfitting refers to a model that functions too well in the training dataset but is less applicable to other datasets. Essentially, the performance of the machine depends strongly on the quality of the data that are used in the training session. It can be problematic if a model learns to use unique features, such as details and noise, which are only present in the training data. Moreover, the ŌĆ£black boxŌĆØ characteristics of the machine may augment this problem. Therefore, it is mandatory to develop standardized methods to test the function of various machine models, which may be in common use in the near future, thoroughly and precisely.
Clinical applications
AI techniques have been applied to stroke imaging in the following two respects: 1) automatic or accurate diagnosis and 2) prediction of prognosis (Table 1).
Diagnosis
Automatic lesion identification or segmentation is one of the most important elements in precision medicine dealing with huge datasets of brain imaging because manual lesion segmentation is cumbersome and inconsistent across raters [10,11]. In addition, automatic lesion identification may expedite accurate diagnoses by non-neurologists. However, automatic segmentation in magnetic resonance imaging (MRI) is not an easy task. The lesion shapes and locations vary according to time-from-symptom onset, vessel occlusion site, and collateral status [12]. Noise related to lesion signals, such as leukoaraiosis, T2 shine-through effects, and tissue defects, may further hamper lesion segmentation. Accordingly, a number of attempts have been made to delineate stroke lesions automatically using machine learning techniques [13-17] but have failed to demonstrate superiority over human manual segmentation [15-17].
Machine learning techniques have only recently begun to show some promising results, comparable to manual segmentation, in chronic stroke [18]. In that study, the authors proposed a supervised lesion segmentation algorithm in T1-weighted imaging. They built a machine with a dataset of 60 left-hemispheric chronic stroke patients (post-stroke interval 2.6┬▒2 years), and tested their model in an independent dataset of an additional 45 patients. The correlations between the predicted manual lesion volume and the predicted lesion volume were r=0.961 for the former and r=0.957 for the latter datasets, respectively.
More recently, the CNN deep learning technique has been applied to lesion segmentation of acute ischemic stroke with diffusion-weighted imaging (DWI) [19]. Two already available CNNs were used together to develop their model: one CNN was an ensemble of two DeconvNets (EDD Net) and the other CNN was a multi-scale convolutional label evaluation net (MUSCLE Net), which aimed to evaluate the results from the EDD Net, removing potential false positives. DWIs from a total of 380 patients were used to train and validate CNNs, and another 361 DWIs were used for testing the model. The mean accuracy of the Dice coefficient (the quotient of pixel-overlap between the candidate segmentation and the manual segmentation; range: 0ŌłÆ1) was 0.67, which was higher than any previous results from the other groups [19], while the detection rate (the quotient of overlap between the number of subjects with any true-positive lesion detections and the number of all subjects) was 0.94. This study was notable because it did not use any manual editing method during training or developing of the machine (unsupervised learning).
Machine learning-based diagnosis by means of computed tomography (CT) has also been attempted. The Alberta Stroke Program Early Computed Tomography Score (ASPECTS), a topographic scoring system for acute ischemic damage to the brain, was automatically assessed using the e-ASPECTS software [20,21]. This software is a standardized, fully automated, CE (Conformit├® Europ├®ene, European Conformity)-mark approved, commercial ASPECTS scoring tool (Brainomix Ltd., Oxford, UK). Remarkably, e-ASPECTS showed a non-inferior performance in reading a total of 2,640 regions (132 patients├Ś20 regions per patient) to that of stroke experts in the assessment of brain CT using ASPECTS.
An attempt was also made to detect the hyperdense middle cerebral artery (MCA) dot sign on CT, which represents a thromboembolus in acute MCA infarcts, using machine learning [22]. To accomplish this, the authors isolated the Sylvian fissure region, extracting several features, and classified the candidates using a SVM classifier. A total of 297 CT images (from 7 patients) were initially considered; 109 CT images with extracted regions of the Sylvian fissure regions were eventually used, which contained 40 islands of the MCA dot sign. The performance was examined using a leave-one-case-out method (cross-validation tool). This system achieved a sensitivity of 97.5% (39/40) for detection of the MCA dot sign at a false-positive rate of 0.5 per image (54 false-positive MCA dot signals/109 CT images) on the cerebral hemisphere suspected of acute stroke.
In patients with a malignant hemispheric infarct, automated quantification of cerebral edema has been attempted [23]. The authors of that article had previously proposed that a reduction in cerebrospinal fluid (CSF) volume on serial CT scans constituted an early and sensitive biomarker of cerebral edema; changes in CSF volumes from baseline to follow-up scans (ΔCSF) was strongly correlated with a midline shift at peak edema [24]. Because manual segmentation of hemispheric CSF on serial CT scans is time-consuming and clinically impractical, the authors developed and validated an automated technique for CSF segmentation via integration of random forest-based machine learning with geodesic active contour segmentation [23]. The algorithm demonstrated excellent results in measuring ΔCSF, which were well-correlated with those from manual segmentation (Pearson coefficient r=0.879, P<10-6). In terms of intracranial hemorrhage (ICH), automatic segmentation of CT lesions has also been successfully achieved [25]. This automated method was more accurate in estimating ICH volume than the conventional ABC/2 method.
Prognosis
Knowing stroke prognosis assists in making clinical decisions [26]. Prediction of treatment complications may be useful for screening a high-risk group receiving acute treatment, such as thrombolysis [27], whereas prediction of neurological long-term outcomes may guide stroke management [28].
Despite its rarity, symptomatic ICH remains a feared complication of acute thrombolysis [29]. Several prognostic scoring systems, such as the Hemorrhage After Thrombolysis (HAT) and Sugar, Early infarct signs, Dense cerebral artery sign, Age, and National Institute of Health Stroke Scale (SEDAN) scores, have been developed for estimating the risk of symptomatic ICH [30,31]; however, external validation of these scores failed to demonstrate convincing results [32,33]. Recently, machine learning of CT images has been attempted for predicting the symptomatic ICH risk with a small cohort of acute ischemic stroke patients [27]. The authors retrospectively used CT brain scan images of 116 acute ischemic stroke patients who were treated with intravenous thrombolysis (including 16 who developed symptomatic ICH), and split these into training (n=106) and test sets (n=10), repeatedly, involving 1,760 different combinations. These CT brain scan images were used as inputs into an SVM, along with clinical severity, to predict the risk of symptomatic ICH. Remarkably, the predictive performance of this SVM-based model (area under the receiver operating characteristic curve [AUC] 0.744, 95% confidence intervals [CIs] 0.738ŌłÆ0.748) was superior to those of established prognostication tools, such as the HAT (AUC 0.629, 95% CIs 0.628ŌłÆ0.630) and SEDAN (AUC 0.626, 95% CIs 0.625ŌłÆ0.627) scores.
Imaging findings are not always a target of machine learning, but can be used as an input feature in machines, for predicting stroke prognosis. In patients (n=35) with posterior cerebral artery infarcts, an SVM-based model, which integrates the regional extent of ischemic lesions and other clinical variables, has successfully predicted the improvement in visual field defects at 3 months [28]. In addition, in patients with brain arteriovenous malformation, a machine learning model using neural networks showed superior accuracy (97.5%) for predicting fatal outcome after endovascular treatment over a mean follow-up of 5 years, while a conventional regression model demonstrated an accuracy of 43% [34]. Recently, findings in both functional and structural MRI have also been used as input features in machine learning to predict post-stroke outcomes, such as motor dysfunction [35] and impairment in multiple behavioral domains [36].
Future
AI techniques in stroke imaging could markedly change the milieu of stroke diagnosis and management in the near future. Automated diagnosis of stroke may be popular in an era where fast thrombolysis, and even prehospital thrombolysis, is recommended [37-40]. The machine-based diagnosis would be particularly helpful for medical staff who are not accustomed to stroke imaging, such as general practitioners or paramedics; the decision to give thrombolysis may be thus be markedly faster. Prediction of prognosis with AI techniques will also be widely used in stroke management. A precise risk stratification for stroke treatment, such as acute thrombolysis or intervention, would be made possible. In addition, foreseeing the degree of post-stroke recovery in advance and informing patients/family members of the prognosis may enhance the treatment rapport and rehabilitation processes.
Perspectives
Establishing a well-constructed, large imaging database is a prerequisite for grafting AI techniques successfully into stroke-imaging analysis. This imaging database should be integrated and interpreted along with other large databases, containing clinical and biological data.
Construction of a ŌĆ£bigŌĆØ database for stroke imaging
Imaging the brain is a sine qua non in stroke medicine, and is obtained at every stage of stroke diagnosis and management [41-46]. Moreover, even a single brain imaging scan contains a number of MRI/CT sequences, which consist of numerous brain slices. In clinical practice, an enormous amount of imaging data is thus rapidly accumulated. Generally, however, such imaging data are not appropriately stored in many hospitals and are rather abandoned after a limited time period. Because AI techniques require a large database to function efficiently, it is imperative to collect imaging data in a structured and systematic way. Cooperative efforts across multiple hospitals and centers are indispensable. On the basis of these necessities, there has recently been a move to gather stroke imaging data worldwide [47,48]. The aim is to build a Million Brains Initiative of real world data for precision medicine in stroke. Besides the global cooperation, there are also many pre-conditions that need to be addressed, such as standardization of imaging protocols, and development of a user-friendly image-uploading server, as well as a cloud system with huge storage capacity. In addition, it is also necessary to build a stroke imaging database of high quality. The accuracy of the dataset, and particularly of the training dataset, is vital for machines to perform reliably. This high-quality database may also facilitate the process of developing novel important imaging parameters and reliable quantification methods. Moreover, it would be challenging to determine who should lead the data collection and analysis processes. Therefore, continuous and enthusiastic efforts across continents and countries are mandatory if a successful imaging database is to be established.
Imaging as a block of ŌĆ£biggerŌĆØ data
Stroke patients present a large amount of varied data, which include clinical, biological (genetic, immunological, and serological markers), in addition to imaging information. Although these datasets are huge, ever-changing over time, difficult to collect systemically, and often lack value in terms of clinical meaning, they are evidently important for defining stroke characteristics and for predicting the prognosis of stroke [1,6]. Currently, novel histological information derived from proteomic analysis of clots retrieved during thrombectomy [49] or cerebrovascular endothelial cells captured from stent retrievers has also emerged. Understanding these multidimensional large datasets is essential in precision medicine, for choosing optimal management in an individual patient, and is the way of the future (issues related to such precision medicine have been thoroughly reviewed by Hinman et al.) [6]. Because not only imaging, but also clinical and biological data, are important in terms of stroke characteristics, stroke imaging data should be interpreted along with the layers of other dimensional data to analyze stroke prognosis and weigh the treatment options. Remarkably, AI-based analysis would also be mandatory in these interpretations. Therefore, efforts to decipher huge multidimensional datasets should run parallel with application of AI techniques in the analysis of stroke imaging.
Conclusions
Although AI techniques in medicine are in their infancy, they have been enthusiastically applied to stroke imaging analysis, showing some encouraging results. The future role of AI techniques in stroke medicine may be promising, because large databases of imaging and other parameters are exponentially being accumulated. Global cooperation and efforts are mandatory to expedite this process.